testPaper
google protobuf协议
参考https://zhuanlan.zhihu.com/p/141415216
简介
google公司内部使用的混合语言数据标准,用于rpc系统和持续数据存储系统
对绝对值较小的数据和量少的字符串等能保证数据传输量足够小的同时,解析快过许多其他数据交换格式。支持10种开发语言的api。
使用
去github上下载源码再解压编译安装
#编译命令
tar -xzf protobuf-2.1.0.tar.gz
cd protobuf-2.1.0
./configure –prefix=$INSTALL_DIR
make
make check
make install
演示案例数据类型用xml表示如下
<helloworld> |
编写.proto内容如下
package lm; |
将上述的.proto文件用protobuf编译器编译成目标语言c++
protoc -I=$src_dir –cpp_out=$dst_dir $src_dir/addressbook.proto
此命令将生成两个文件:Im.helloworld.pb.h和Im.helloworld.pb.cc(c++头文件和类的实现文件)头文件中定义了一个类helloworld,能对消息进行操作,赋值以及序列化。
writer和reader
数据传输文件中总需要分隔符方便读取,但proto不需要,或者说其分隔符只占一位,分隔的工作交给程序实现。


将传输的方式从磁盘改为网络即可实现网络数据交换。
和其他的对比
protobuf难以表示复杂的概念,且因为基于二进制存储,所以只有知道.proto定义的reader和writer程序能直接读取编辑
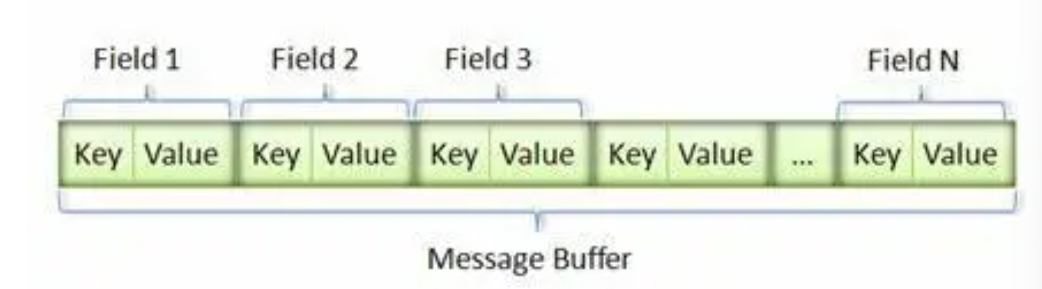
.proto的结构
varint编码
此编码实现了极简的分隔功能

每一字节最高位的1或0表示这字节的数据是否和下一字节连续。因此只需要读取对应最高位即可序列化为键值对,不需要语法分析。
zigzag编码
这种编码将正负位置于数据末尾,对本身绝对值特别小的数据特别友好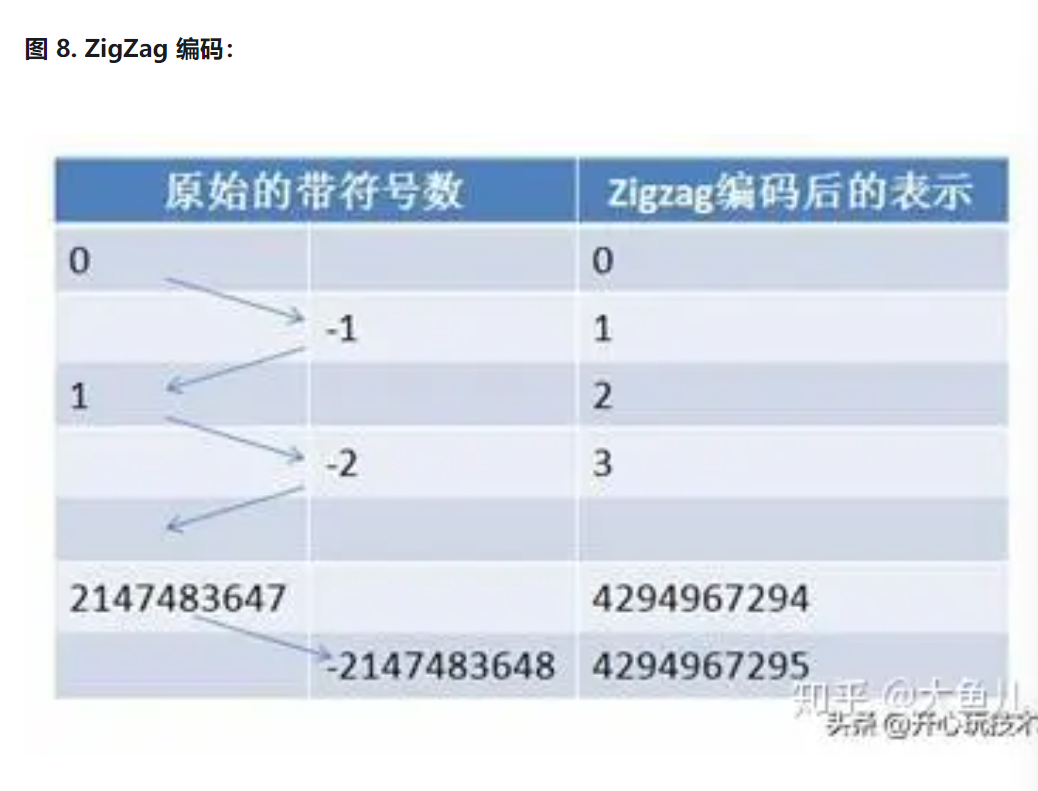
其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。